AI를 더 똑똑하게: LLM, RAG, 온톨로지의 삼각관계
AI가 그럴듯하지만 틀린 답을 하는 이유는 무엇일까? 이 글은 LLM의 구조적 한계에서 출발해 RAG의 검색 기반 보완 방식, 온톨로지가 제공하는 개념 관계 구조까지 단계적으로 설명한다. 또한 세 기술을 결합했을 때 장점과 오류 증폭 루프의 위험, 실무 설계 시 고려해야 할 3단계 전략을 함께 정리해 AI 신뢰도를 높이는 방법을 제시한다.

왜 AI는 가끔 그럴듯한 거짓말을 할까?
챗지피티나 클로드 같은 AI에게 질문을 던지면 대부분 매끄럽게 답을 줍니다. 그런데 가끔 이런 일이 생깁니다. 내용은 그럴듯하지만 사실이 아닌 답을 하거나 법 조문을 잘못 인용하거나 존재하지 않는 논문을 태연하게 제시하는 경우가 있습니다.
왜 그럴까요? 많은 LLM은 방대한 텍스트를 학습해 다음에 올 말(토큰)을 예측하는 방식으로 작동합니다. 이 구조는 문장을 자연스럽게 만드는 데는 탁월하지만 답이 사실인지를 스스로 검증하는 기능까지 기본으로 갖춘 것은 아닙니다. 이 문제를 줄이기 위해 연구자들은 여러 보완 기술을 발전시켜 왔습니다. 이 글에서는 그중 핵심적으로 언급되는 세 가지, LLM, RAG, 온톨로지가 어떤 역할을 하고 어떻게 결합될 수 있는지 차근차근 살펴보겠습니다.
첫 번째 주인공: LLM(대형 언어 모델)
LLM(Large Language Model)은 아주 많은 텍스트를 학습해 다음에 어떤 말이 오면 자연스러운가를 잘 맞히는 AI 엔진입니다. 챗지피티, 클로드, 제미나이 등이 여기에 해당합니다.
쉽게 말하면 엄청나게 많은 글을 읽고 글 쓰는 법을 익힌 AI입니다. LLM은 질문에 대한 답변을 작성하는 능력이 뛰어납니다. 다만 학습 시점 이후의 최신 정보, 특정 조직이나 도메인에만 존재하는 내부 규정, 또는 정확한 수치처럼 근거 확인이 중요한 영역에서는 틀릴 수 있습니다.
두 번째 주인공: RAG(검색 기반 생성)
RAG(Retrieval-Augmented Generation)는 '검색(Retrieval) + 생성(Generation)'의 합성어입니다. AI가 답을 만들기 전에 먼저 관련 문서를 찾아보고, 그 내용을 참고해 답하게 만드는 방식입니다. 마치 시험 전에 교과서를 펼쳐 확인하는 것과 비슷합니다.
RAG는 데이터의 근거를 가져오는 파이프라인이라고 볼 수 있습니다. 보통은 검색, 관련 문서(또는 문서 조각) 선별, LLM에 전달, 답변 생성의 순서로 흐릅니다. 이용자가 질문을 던지면 RAG는 먼저 관련 문서 더미에서 관련성 높은 내용을 꺼내 옵니다. 그리고 그 내용을 LLM에게 넘겨주며 이렇게 말하는 셈입니다.
자, 이 자료를 참고해서 답을 써줘.
덕분에 LLM은 자기 기억(학습된 패턴)만으로 답하는 것이 아니라 실제 문서를 근거로 답할 가능성이 높아집니다.
세 번째 주인공: 온톨로지(개념 지도)
온톨로지(Ontology)는 원래 철학에서 온 용어지만 정보과학에서는 개념(용어)과 그 관계를 체계적으로 정리한 지식 구조를 뜻합니다. 예를 들어 다음과 같은 관계를 규칙처럼 정리해 둔 것입니다.
- “아스피린은 해열제다.”
- “해열제는 의약품의 한 종류다.”
- “의약품은 처방전이 필요한 것과 필요하지 않은 것으로 나뉜다.”
온톨로지는 한마디로 개념 사이 관계를 명시해 둔 지도입니다. 일반적인 RAG가 주로 텍스트 유사도(또는 벡터 유사도)를 기준으로 문서를 찾는다면 온톨로지는 이 개념은 저 개념과 어떤 관계다, 라는 구조 정보를 제공해 검색과 연결을 더 정밀하게 만들 수 있습니다.
셋을 함께 쓰면 무엇이 좋아질까?
LLM만 쓰면 무엇이 달라질까?
예를 들어 AI에게 “우리 회사 취업 규칙 위반 시 처리 절차가 뭐야?”라고 물어보면 그럴듯한 일반론을 길게 늘어놓을 겁니다. 하지만 그 답은 여러 회사에 통할 법한 일반적인 설명일 뿐 해당 회사의 실제 규정이 아닐 가능성이 큽니다. LLM이 그 회사의 내규 문서를 직접 참고하지 않았기 때문입니다.
RAG를 더하면 해결될까?
많이 나아집니다. 이제 AI가 회사 내규 문서를 검색해 참고할 수 있기 때문입니다. 다만 여기서 새로운 문제가 생길 수 있습니다. 일반적인 RAG는 종종 벡터 유사도 기반으로 문서 조각을 가져옵니다. 벡터 유사도(Vector Similarity)는 단어나 문장을 숫자 좌표(벡터)로 바꾼 뒤 그 좌표가 가까운 것끼리 비슷하다고 판단하는 방법입니다. 지도에서 거리가 가까운 두 도시처럼 숫자 공간에서 가까운 개념들을 묶어 냅니다.
이 기준에 따라 징계 절차를 검색하면 징계가 언급된 조각들이 모이는데 이때 논리적으로 이어져야 할 내용이 흩어져 들어올 수 있습니다. 예를 들어 징계 사유는 3조, 처리 절차는 15조, 이의 신청 방법은 22조처럼 떨어져 있는데, 이것들이 하나의 규칙 체계라는 사실을 RAG가 자동으로 이해하고 묶어 주지는 못할 수 있습니다.
이 방식은 유용하지만 왜 이 문서들이 함께 묶여야 하는지 같은 의미 구조와 규칙 체계까지 항상 보장해 주는 것은 아닙니다. 그래서 관련 문서는 가져왔는데도, 답이 어딘가 빠져 있거나 문맥이 어색해지는 경우가 생깁니다.
그래서 온톨로지가 도움이 될 수 있다
예를 들어 징계 처리라는 개념을 검색하면 온톨로지는 그 개념과 연결된 사유 조항 → 절차 조항 → 이의 신청 조항 같은 관계를 구조로 갖고 있을 수 있습니다. 이런 구조를 결합하면 RAG가 문서를 가져올 때 한 덩어리의 규칙 체계를 더 잘 유지하도록 설계할 수 있습니다.
문서 조각을 개별 카드처럼 다루기보다 관계 중심으로 묶어 표현하기도 합니다. 이때 등장하는 표현 중 하나가 하이퍼그래프(Hypergraph)입니다. 하이퍼그래프는 일반 그래프(선이 보통 두 노드를 잇는 구조)와 달리, 하나의 연결(하이퍼엣지)이 세 개 이상의 개념을 동시에 묶을 수 있는 구조입니다. 예를 들어 아스피린 복용이라는 행위는 발열 완화, 통증 감소, 위장 자극과 같은 용어와 한 덩어리로 볼 수 있습니다.
새로운 흐름: LLM이 온톨로지를 만든다
한 가지 흥미로운 변화는, 원래 전문가가 손으로 만들던 온톨로지를 LLM이 초안 형태로 자동 추출하는 시도가 늘고 있다는 점입니다. 예를 들어 LLM은 텍스트에서 다음 작업을 보조할 수 있습니다.
- 개념의 유형 분류(Term Typing)
- 계층 관계 발견(Taxonomy Discovery)
- 비계층적 관계 추출(Non-taxonomic Relation Extraction)
텍소노미(Taxonomy)는 생물 분류처럼 상위-하위 관계로 정리된 계층 구조입니다. 동물 → 포유류 → 고양이과 → 집고양이가 전형적인 예시입니다. 중요한 점은 LLM이 만드는 온톨로지가 보통 완성된 전문가 산출물이라기보다 반자동 초안에 가깝다는 것입니다. 따라서 실제 운영 환경에 쓰려면 여전히 전문가 검토와 품질 관리가 필요합니다.
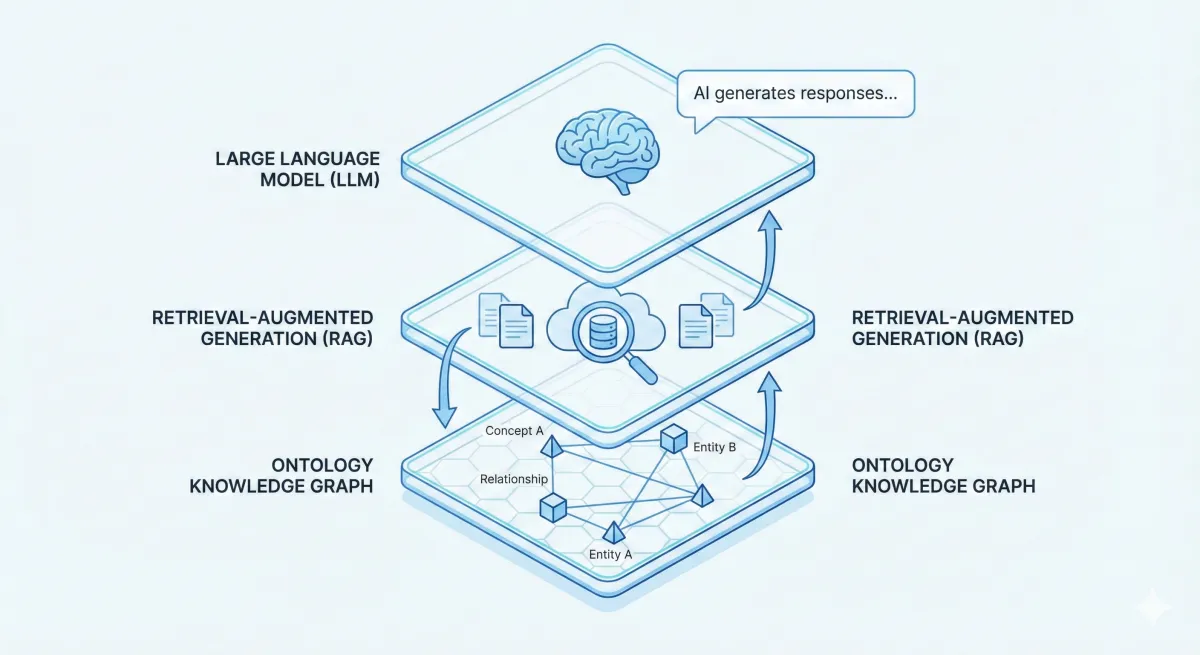
전체 그림: 세 기술의 협력 구조
지금까지 설명한 내용을 하나로 묶으면 다음과 같습니다.
[사람의 질문]
↓
[RAG: 관련 정보 검색]
↑
[온톨로지: 의미 구조로 검색 정밀화]
↓
[LLM: 검색 결과를 바탕으로 답변 생성]
↓
[사람에게 전달]
그리고 동시에:
[LLM: 텍스트에서 온톨로지 구조 추출 보조]
↓
[온톨로지: 전문가 검토 후 고도화]
↓
[다시 RAG를 더 정확하게]
실무에서 어떻게 설계할까?
세 단계로 정리하면 이렇습니다.
A 단계: LLM만 사용할 때 빠르고 편리합니다. 하지만 최신 정보, 정확한 수치, 도메인 전문 규칙에는 취약합니다. 일반적인 글쓰기나 요약에는 충분합니다.
B 단계: LLM + RAG를 함께 쓸 때 문서 기반 검색으로 신뢰도가 올라갑니다. 그러나 개념 간 관계나 규칙 체계가 중요한 질문에는 검색 노이즈가 남을 수 있습니다. 검색 노이즈(Retrieval Noise)란 관련성은 있어 보이지만 실제로는 불필요하거나 맥락을 흐트러뜨리는 검색 결과를 말합니다.
C 단계: LLM + RAG + 온톨로지를 함께 쓸 때 검색 단계에서 개념과 관계로 필터링하고 확장합니다. 문맥 구성에서 규정-예외, 상하위, 절차 흐름을 유지하도록 설계할 수 있습니다. 생성 단계에서 도메인 규칙을 위반할 가능성을 낮추는 데 도움이 됩니다. 법률, 의료, 산업 현장처럼 정확성이 핵심인 환경에 특히 유용합니다.
그러나 이 순환에는 함정이 있다
LLM이 온톨로지를 만들고 그 온톨로지로 RAG를 개선하고 더 나은 LLM이 더 나은 온톨로지를 만드는 선순환은 매력적으로 들립니다. 하지만 여기에는 진지하게 고려해야 할 위험이 있습니다.
LLM이 자동으로 생성한 온톨로지에 오류가 있다고 가정해 보겠습니다. 그 온톨로지를 기반으로 RAG가 검색하면 잘못된 정보가 LLM에게 전달됩니다. 그러면 LLM이 그것을 정제된 구조인 양 다시 사용하게 되어 오류가 증폭되는 루프가 생길 수 있습니다. 그래서 실무에서는 보통 다음 원칙이 중요합니다.
- LLM이 자동 생성한 온톨로지(초안)와 전문가가 검증한 온톨로지(확정본)를 구분한다.
- 검증 전 온톨로지는 RAG의 핵심 기준점(앵커)으로 직접 쓰지 않는다.
여기서 앵커(anchor)는 검색과 확장의 기준점이 되는 핵심 개념을 뜻합니다. 이 개념을 중심으로 가져와라, 는 뜻입니다.
세 기술이 함께할 때 비로소 완성된다
LLM은 글을 잘 쓰지만 사실 확인이 약합니다. RAG는 문서를 가져오지만 그 문서들 사이의 관계는 모릅니다. 온톨로지는 개념 지도를 갖고 있지만 혼자서는 아무것도 못 씁니다.
셋이 역할을 나눠 붙으면 근거 있고 맥락이 이어지는 답변이 나옵니다. 법률이나 의료처럼 틀리면 안 되는 영역에서 AI를 실제로 쓰려면 이 셋의 조합을 이해해 두는 게 좋습니다.
핵심 용어
| 용어 | 한 줄 설명 |
|---|---|
| LLM | 방대한 텍스트를 학습해 글을 쓰는 AI 엔진 |
| RAG | AI가 답하기 전에 관련 문서를 검색해 참고하게 하는 방법 |
| 온톨로지 | 개념들 사이의 관계를 정리한 구조화된 지식 지도 |
| 벡터 유사도 | 단어·문장을 숫자로 변환해 “가까운 것 = 비슷한 것”으로 판단하는 방법 |
| 하이퍼그래프 | 여러 개념을 동시에 연결하는 고차원 관계 표현 구조 |
| 임베딩 | 단어·문장을 숫자 벡터로 변환하는 과정 |
| 지식 그래프(KG) | 개념과 개념 사이의 관계를 점과 선으로 표현한 관계형 데이터 구조(그래프) |
| GraphRAG | 지식 그래프 구조를 활용하는 RAG 변형 방식 |
| 검색 노이즈 | 관련 있어 보이지만 맥락을 흐트러뜨리는 불필요한 검색 결과 |
| 앵커 | 검색의 기준점이 되는 핵심 개념 |
| 파이프라인 | 여러 처리 단계가 순서대로 연결된 자동화 흐름 |



